
Introduction:
In the world of DevOps and cloud computing, Kubernetes has become a household name. Originally developed by Google, Kubernetes, often referred to as K8s, has revolutionized how applications are deployed, scaled, and managed. This guide will walk you through the fundamentals of Kubernetes, exploring what it is, why it’s crucial, and how it works.
Kubernetes history
1. Origins at Google (2003-2014)
- Borg and Omega Projects: Kubernetes originated from Google’s internal systems, Borg and Omega, which were built to manage large-scale applications and workloads across thousands of machines. Borg, developed in the early 2000s, was one of Google’s first large-scale container orchestration systems and handled tasks like scheduling, scaling, and load balancing.
- Container Technology: Google had extensive experience with containerization even before Docker became mainstream. Their insights into container management were pivotal in creating a powerful open-source container orchestration platform.
2. Rise of Docker (2013)
- Docker’s release in 2013 popularized the use of container technology beyond Google, leading to an increased need for robust container orchestration solutions.
- The adoption of Docker inspired Google to share their expertise by creating an orchestration system that could manage Docker containers, which they did by open-sourcing Kubernetes.
3. Birth of Kubernetes (2014)
- Open-Source Release: In 2014, Google open-sourced Kubernetes as a new project under the Apache 2.0 license. Initially developed by Joe Beda, Brendan Burns, and Craig McLuckie, Kubernetes aimed to bring Google’s extensive knowledge of container management to the open-source community.
- Collaboration with the Linux Foundation: Google partnered with the Linux Foundation to ensure community-driven growth, eventually establishing Kubernetes as a project under the Cloud Native Computing Foundation (CNCF) in 2015.
4. Cloud Native Computing Foundation (CNCF) (2015)
- The CNCF, a part of the Linux Foundation, was created to support the development and adoption of cloud-native software. Kubernetes was the first project accepted by CNCF, which helped foster a strong ecosystem around it.
- With CNCF’s backing, Kubernetes gained rapid adoption, as it received significant contributions from other tech giants and became a central tool in cloud-native environments.
5. Broad Adoption and Ecosystem Growth (2015-2020)
- Kubernetes 1.0 and Beyond: Kubernetes 1.0 was released in mid-2015, and Google donated the project to CNCF. This move facilitated community-led contributions and accelerated innovation around Kubernetes.
- Container Orchestration Standard: By 2017, Kubernetes had become the de facto standard for container orchestration, overtaking other platforms like Docker Swarm and Apache Mesos due to its robust feature set and large community.
- Ecosystem and Tooling: A wide array of Kubernetes-native tools and projects emerged, like Helm for package management, Prometheus for monitoring, and Istio for service mesh architecture.
6. Mainstream Cloud Provider Support and Managed Services (2018-Present)
- As Kubernetes adoption grew, cloud providers like Google Cloud, Amazon Web Services, and Microsoft Azure began offering managed Kubernetes services (GKE, EKS, AKS) to simplify the deployment and management of Kubernetes clusters.
- This allowed organizations to focus on application development without managing infrastructure, accelerating Kubernetes’ adoption across all industries.
7. Maturity and Enterprise Adoption (2020-Present)
- Widespread Enterprise Use: Kubernetes has now become integral in DevOps and infrastructure-as-code practices, with enterprises deploying it in production for scalable, resilient applications.
- Expanded Ecosystem: With ongoing development by the community and CNCF, Kubernetes now supports a variety of workloads, from machine learning and big data processing to traditional web applications.
- Continued Evolution: Kubernetes continues to evolve with features like serverless support (via Knative), multi-cluster management, improved security, and enhancements for better developer experiences.
Today’s Impact
Kubernetes is now synonymous with modern cloud-native applications and has transformed how applications are built, deployed, and scaled. It represents the shift towards microservices, automation, and flexible, multi-cloud environments. With its strong community and continuous innovations, Kubernetes remains a cornerstone of modern infrastructure.
What is Kubernetes?
Kubernetes is an open-source platform designed to automate deploying, scaling, and managing containerized applications. With Kubernetes, you can group containers that make up an application into logical units for easier management and discovery.
Key Features of Kubernetes:
- Automated Rollouts and Rollbacks: Manages the deployment of applications and handles rollbacks if necessary.
- Service Discovery and Load Balancing: Exposes a container using the DNS name or an IP address and balances the load across multiple containers.
- Storage Orchestration: Automatically mounts storage systems as needed.
- Self-Healing: Restarts failed containers and replaces and reschedules containers when nodes die.
Why Kubernetes?
The rise of microservices architecture and containerization (like Docker) made managing complex systems a challenge. Kubernetes provides a solution by allowing developers to manage and orchestrate containers efficiently. Here are some compelling reasons to use Kubernetes:
- Scalability: Easily scales applications up or down based on demand.
- Cost Efficiency: Optimizes resource usage, which can lower costs in cloud environments.
- Improved CI/CD: Kubernetes integrates seamlessly with CI/CD tools, enabling smoother, more reliable deployments.
- Flexibility and Portability: Works with any container runtime and can run on various environments, from on-premises servers to cloud infrastructure.
Kubernetes Architecture: Components and Concepts
Understanding Kubernetes requires a grasp of its architecture. It has a master-worker node setup:
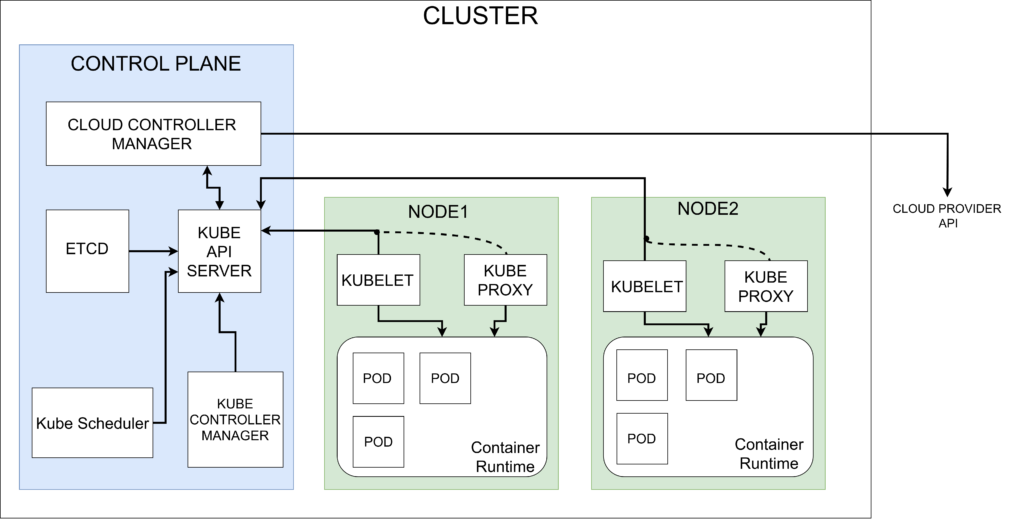
- Master Node Components:
- API Server: Acts as the frontend for Kubernetes. All communications to the cluster go through this server.
- Controller Manager: Manages the state of the cluster, including application deployment and scaling.
- Scheduler: Assigns workloads to nodes based on resource availability.
- etcd: A distributed key-value store that holds the configuration data and state of the cluster.
- Worker Node Components:
- Kubelet: Ensures containers are running in a Pod on a node.
- Kube-proxy: Manages network connectivity for services on nodes.
- Container Runtime: Such as Docker or containerd, which runs the actual containers.
- Other Key Concepts:
- Pods: The smallest deployable units that can contain one or multiple containers.
- Services: Expose Pods to the network and enable communication between different services.
- Namespaces: Provide a way to divide cluster resources among multiple users or teams..
1. Master Node (Control Plane)
The control plane, or master node, manages the Kubernetes cluster, orchestrating scheduling, scaling, and overall control of workloads. It includes the following key components:
- API Server (kube-apiserver): The API server is the entry point for all administrative tasks and communicates with the Kubernetes cluster using RESTful APIs. It processes requests (e.g., from
kubectl, client apps) and exposes the Kubernetes API. - Scheduler (kube-scheduler): The scheduler assigns newly created Pods to suitable worker nodes based on factors like available resources, node affinity/anti-affinity, and workload requirements.
- Controller Manager (kube-controller-manager): The controller manager handles the core controllers in Kubernetes (e.g., node controller, deployment controller). It ensures the desired state of the cluster aligns with the actual state.
- etcd:
etcdis a distributed key-value store that stores all cluster data persistently, including configuration details, secrets, and network policies. It serves as the source of truth for Kubernetes state. - Cloud Controller Manager: If a Kubernetes cluster is deployed on a cloud provider, this component integrates with cloud-specific services like load balancers, storage, and auto-scaling.
2. Worker Node (Node Components)
Each worker node runs Pods and is managed by the control plane. Worker nodes host several critical components:
- Kubelet: The kubelet is an agent that runs on each node, listening for instructions from the API server. It ensures containers in Pods are running as expected and maintains the node’s health.
- Kube-proxy: The kube-proxy manages network rules for connecting Pods across nodes, implementing Kubernetes Service networking and routing traffic to correct Pods based on Service configurations.
- Container Runtime (e.g., Docker, containerd, CRI-O): This is the software responsible for running containers on each node. Kubernetes supports multiple runtimes via the Container Runtime Interface (CRI).
3. Cluster-Level Components and Resources
Kubernetes clusters have several cluster-level constructs that allow orchestrating complex applications and services:
- Pods: The smallest deployable unit in Kubernetes, a Pod usually represents one application instance. A Pod can contain one or more containers and shares networking and storage resources.
- ReplicaSet: Ensures a specified number of Pod replicas are running. If a Pod fails, the ReplicaSet will create new Pods to meet the desired replica count.
- Deployment: A higher-level abstraction over ReplicaSets, Deployments provide declarative updates to applications. They allow you to define how many replicas are required and manage rolling updates and rollbacks.
- DaemonSet: Ensures a Pod is running on every (or selected) node, useful for running system services like logging and monitoring agents.
- StatefulSet: Manages Pods with unique identities and stable storage, ideal for stateful applications (e.g., databases).
- Job and CronJob: Jobs handle tasks that need to run to completion, while CronJobs schedule tasks to run periodically.
4. Networking and Service Abstraction
Networking is fundamental in Kubernetes for communication within and outside the cluster:
- Service: Services abstract network access to a set of Pods. They can expose applications internally or externally within the cluster. Types include:
- ClusterIP: Default service type, exposes the Service only within the cluster.
- NodePort: Exposes the Service on a specific port of each node’s IP.
- LoadBalancer: Provisions an external load balancer (typically used with cloud providers).
- Network Policies: Define rules that specify how Pods are allowed to communicate with each other and other network endpoints. It allows traffic to be secured by controlling inbound and outbound connections.
5. Storage
Kubernetes provides several mechanisms to manage persistent data for stateful applications:
- Persistent Volumes (PV): A PV is a piece of storage in the cluster that an administrator has provisioned. It is independent of any particular Pod or namespace.
- Persistent Volume Claims (PVC): PVCs are requests for storage by applications. Pods use PVCs to claim PVs to store data persistently.
- Storage Classes: Define different types of storage (e.g., SSDs, network-attached storage) and are used by PVCs to dynamically provision PVs as per the requirements.
6. Configuration Management
Configuration management allows separating configuration data from code, making it easy to update and manage application settings:
- ConfigMaps: Store configuration data in key-value pairs, such as environment variables, which can be injected into Pods.
- Secrets: Similar to ConfigMaps, but designed to store sensitive information (e.g., passwords, API tokens) in an encrypted format.
7. Ingress and External Access
- Ingress: An API object that manages external access to services, typically HTTP. It provides rules for routing external traffic to Services within the cluster and can manage TLS termination for HTTPS access.
8. Authentication and Authorization
Kubernetes ensures secure access through several methods:
- Authentication: Can be managed using certificates, tokens, or integration with cloud provider credentials.
- Role-Based Access Control (RBAC): Allows administrators to define access control policies based on roles and responsibilities, restricting actions based on the principle of least privilege.
9. Observability and Monitoring
Monitoring is essential for managing and troubleshooting clusters:
- Metrics Server: Provides metrics about resource usage, which can be used by the Horizontal Pod Autoscaler (HPA) to scale applications based on CPU or memory usage.
- Logging and Monitoring Tools: Kubernetes clusters are often integrated with monitoring tools like Prometheus and Grafana for detailed observability, as well as logging solutions like Elasticsearch and Fluentd for log aggregation and analysis.
10. Autoscaling
Autoscaling in Kubernetes provides dynamic adjustment of resources based on load:
- Horizontal Pod Autoscaler (HPA): Scales the number of Pod replicas based on observed CPU or memory metrics or custom metrics.
- Vertical Pod Autoscaler (VPA): Adjusts the resource requests and limits of containers in a Pod based on usage patterns.
- Cluster Autoscaler: Works with cloud providers to add or remove nodes from the cluster based on the demands of the workloads running.
Key Concepts and Summary
- Declarative Configuration: Kubernetes relies on a desired-state configuration, meaning you declare the desired state in manifest files (YAML), and Kubernetes adjusts the actual state to match it.
- Self-Healing: Kubernetes monitors and maintains the health of applications by automatically restarting failed containers, rescheduling Pods on different nodes, and killing unhealthy Pods.
- Scalability: Through horizontal scaling (adding more Pods) and vertical scaling (adjusting resources), Kubernetes can handle a wide range of workloads, from small applications to large-scale enterprise deployments.
How Does Kubernetes Work? (Basic Workflow)
Here’s a simple walkthrough of how Kubernetes operates:
- Container Creation: First, you define a containerized application, typically using Docker.
- Create YAML Files: Describe how the application should be deployed (like Pods, services, and deployments) in YAML files.
- Apply Configuration: Use the
kubectlcommand to deploy the configuration. Kubernetes reads the YAML and creates the necessary resources. - Automatic Management: Kubernetes will now manage the application. It can restart failed Pods, scale based on traffic, and handle networking and storage needs.
Real-World Use Cases of Kubernetes
Kubernetes is widely used across various industries. Here are some popular use cases:
- Continuous Integration and Continuous Deployment (CI/CD): Automates the deployment of new application versions with zero downtime.
- Microservices Architecture: Allows easy management of different services within an application, making Kubernetes an ideal choice for companies moving from monolithic to microservices.
- Data Processing: Companies like Spotify use Kubernetes to manage large-scale data processing, where resources can be scaled up or down as needed.
Challenges in Kubernetes
Despite its benefits, Kubernetes does have its challenges:
- Complexity: Setting up and managing Kubernetes requires significant expertise.
- Resource Intensive: Running a Kubernetes cluster can be resource-intensive, especially for smaller applications.
- Monitoring and Logging: Managing logs and monitoring cluster health across multiple Pods and nodes can become complex, often requiring third-party tools.
Conclusion: Is Kubernetes Right for You?
Kubernetes has reshaped how applications are deployed and managed. If your application requires high availability, scalability, and efficient resource management, Kubernetes is an excellent choice. However, it may not be necessary for smaller applications or those that don’t require high levels of automation. Assessing your infrastructure needs and application demands can help you decide if Kubernetes is the right choice.